Точное управление GPIO
-
Привет всем! Имеется Raspberry Pi 4B. Мне нужно с него одновременно управлять 20 адресными светодиодными лентами WS2812b. Из-за большого количества лент не получается использовать готовые библиотеки, т.к. они используют аппаратную PWM (широтноимпульсную модуляцию), и мне нужно переключать пины GPIO вручную, быстро и точно. Опытным путем я установил, что если делать 76 раз asm("nop"), то получается точно выдержать интервал 400 нс. Проблема в том, что периодически этот интервал становится гораздо больше, по-видимому из-за прерываний процессора.
Для теста я генерирую кодом меандр с периодом около 800 нс.
Я изолировал четвертое ядро контроллера через cpuisol=3, чтобы ОС (использую Raspbian) не перекидывала другие процессы на 4 ядро, а своей программе напрямую указал привязаться к четвертому ядру, помимо этого, я установил ей максимальный приоритет. Почти получилось выдерживать ровные интервалы, но всё еще периодически происходят сбои, и лента сбивается:
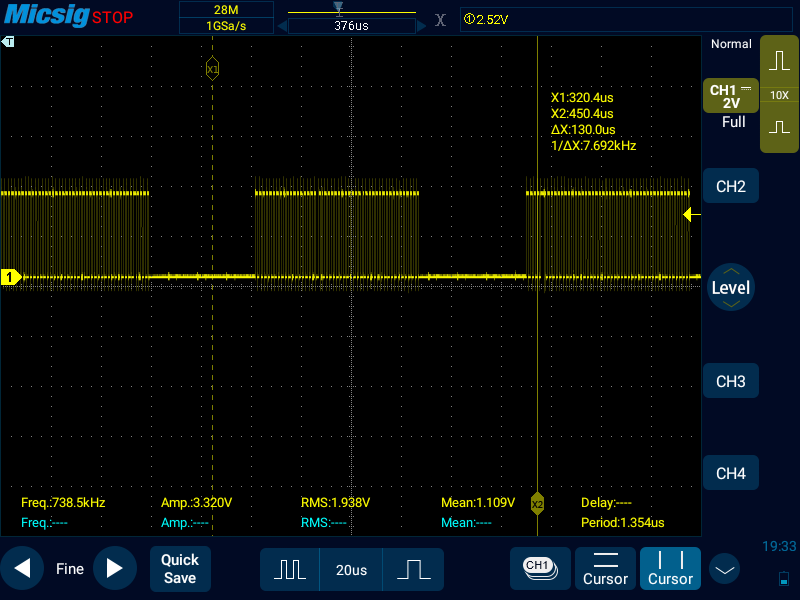
После этого я написал модуль ядра linux, драйвер, который также работает с gpio, только на время передачи данных делает spin_lock_irqsave(), а затем, после передачи данных - spin_unlock_irqsave(), чтобы запретить ОС выполнять прерывания во время передачи данных через GPIO. К моему удивлению, такой код работает даже хуже, чем тот, который работал из userspace без драйверов:
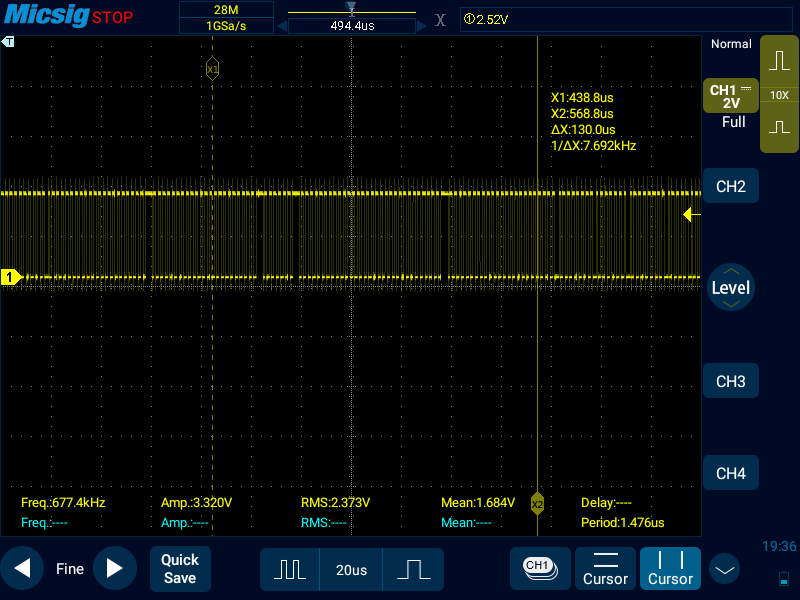
В версии с драйвером сбои происходят каждые несколько периодов, тогда как из userspace сбои достаточно редки.
Вопрос - что я делаю не так? Почему у драйвера результат хуже? Я не до конца отключил прерывания? Или дело в способе работы с gpio - ведь в userspace я работаю через wiringPi.h, а в kernelspace - через linux/gpio.h - может в этом дело? Как мне добиться стабильной работы?
-
*В первом случае каждые 24 периода я осознано делал паузы 50 мкс, это не сбой. Речь именно о том, что "расческа" получается неровная
-
Я уже лет 10 занимался написанием драйверов для линуха, так что некоторый опыт есть. И эти вот Ваши идеи:
если делать 76 раз asm("nop"), то получается точно выдержать интервал 400 нс.
и
на время передачи данных делает spin_lock_irqsave()
кажутся мне довольно странными...Главная задача программиста при написании драйвера - уменьшить временные задержки, вносимые драйвером в работу ОС. А Вы делаете всё, что бы нарушить нормальную работу ядра. Но тогда не стоит удивляться, что результаты получаются какие-то странные!
Я по этим двум пунктам выскажусь так:
Для организации задержек на фиксированный интервал времени в ядре есть набор вызовов:
ndelay(unsigned long nsecs) udelay(unsigned long usecs) mdelay(unsigned long msecs)Я думаю, их вполне достаточно для Ваших целей.
Далее, по поводу блокировки прерываний с помощью spin_lock_irqsave() Эта функция может использоваться только в очень ограниченные периоды времени. Использовать её во время выполнения операций ввода/вывода довольно сомнительно. тем более, если данные передаются из/в userspace. А если нужной страницы из userspace в этот момент нет в оперативной памяти? Я настоятельно рекомендую убрать эти вызовы.
-
Возможно имеет смысл поэксперементировать с ОС реального времени или накатить real time kernel на Raspberry Pi OS
-
@sv-lary#6812 Нюанс в том, что малина кроме получения пакетов по UDP и управления лентами ничего делать не будет, поэтому я и отношусь так спокойно к торможению ядра.
@mojo#6814 Да, походу к этому все идёт. Вопрос - кому нибудь удавалось накатить этот патч на Raspbian на малине 4B? Я слышал с этим патчем постоянно проблемы и много гемора
-
@sv-lary#6812 Далее, по поводу блокировки прерываний с помощью spin_lock_irqsave() Эта функция может использоваться только в очень ограниченные периоды времени. Использовать её во время выполнения операций ввода/вывода довольно сомнительно. тем более, если данные передаются из/в userspace. А если нужной страницы из userspace в этот момент нет в оперативной памяти? Я настоятельно рекомендую убрать эти вызовы.
А как мне тогда добиться точного тайминга? По идее каждые 24 переданных бита я делаю паузу в 50 мкс, и к ней уже требования пониже. Может, стоит тормозить прерывания только на передаче 24 бит и потом на время паузы отпускать? А чтобы нужная страница памяти подгрузилась перед блокировкой 1 раз вхолостую прочитать нужные 24 состояния, потом блокировка, передача, разблокировка и пауза в 50 мкс. Так можно?
-
@VBDUnit#6818 А как мне тогда добиться точного тайминга?
Я же уже говорил - для этого есть семейство ф-ций ядра delay() Честно говоря, я вообще не понимаю, о чём речь. Вы хотите убедить м еня в том, что для передачи 24 бит сколько-то там раз в секунду, нужно всё ядро подвешивать на spin_lock() ?! Я в это не могу поверить.
Скажите, в Вашем драйвере вообще есть функция обработки прерываний? Вы знаете, как управлять вводом/выводом по прерываниям?
-
@sv-lary#6819 С компа идут данные, как выставить цвета на ленте. Мне нужно передавать 30 раз в секунду цвета для 144 светодиодов, по 24 бита на каждый. Бит передается тремя подряд идущими уровнями: единица, затем значение бита, затем ноль. Каждый из этих уровней должен длиться 400 нс. Между светодиодами нужно выдерживать паузу 50 мкс. Это не слишком большой объем данных, но лента очень чувствительна к таймингу, и сбывается при малейшей отклонении.
При этом лент больше 20. Из за этого не получается использовать аппаратный PWM, по этой же причине я использую малину, а не контроллер - если контроллер и переварит 2,5 мбит/с, то задержка будет все равно значительной.
Поэтому я влез в драйверы.
-
И я не пытаюсь что-то там доказать, я новичок, а Вы профессионал, и Вы разбираетесь в теме намного лучше меня. Я лишь уточняю свою цель - мне просто нужно заставить малину железобетонно выдерживать интервалы ровно в 400 нс плюс минус 20 нс без каких либо исключений. Проблема не в количестве данных, а в соблюдении чётких интервалов, потому что лента работает безо всяких коррекций ошибок и ожиданий.
По поводу ndelay. Вот меандр, выдаваемый без ndelay:
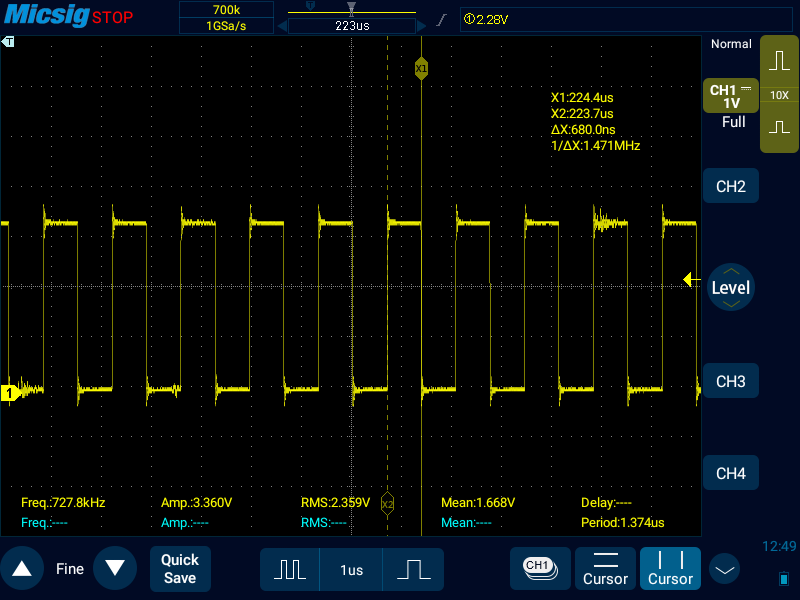
интервал 680 нс получается, по-видимому, потому, что я не использую DMA - собственно, сейчас прикручиванием оного я и занимаюсь. И вот к этому коду после включение, и после и выключения пина я добавляю по ndelay(400). По логике интервал должен стать равными примерно 1 мкс. Но на практике происходит так:
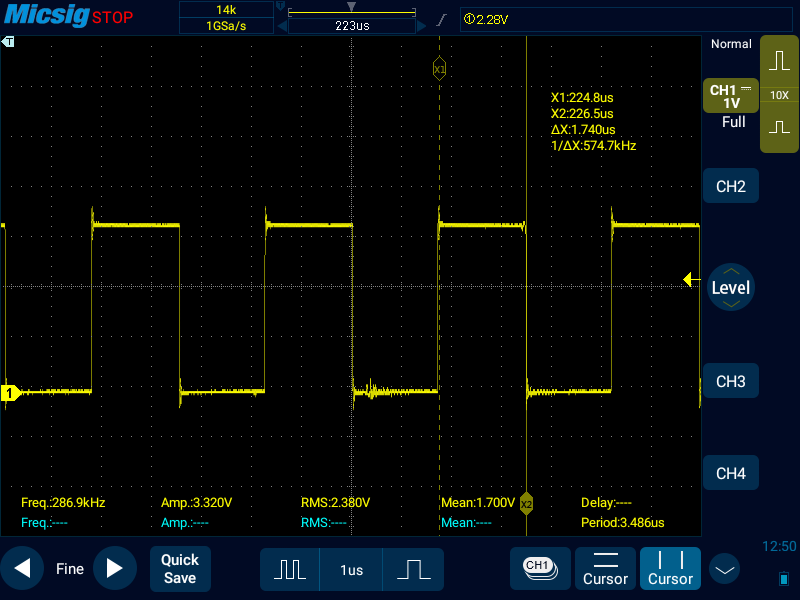
Может я чего-то и не понимаю, но она накинула целую микросекунду, и это совсем не то, что нужно. Окей, попробуем ndelay(1):
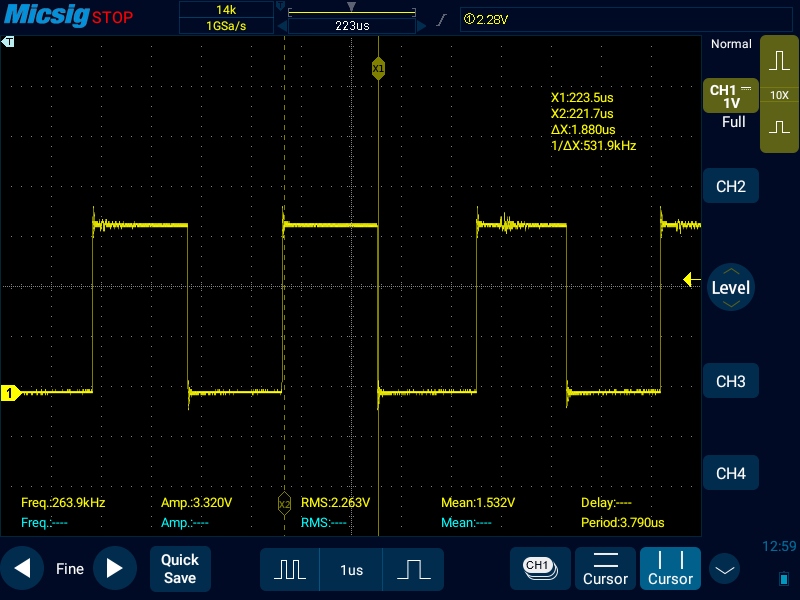
Всё еще печаль. Видимо сам вызов ndelay занимает неприемлемо большой интервал времени.Все эти выделения памяти с отключением кеширования и отключение прерываний я использую лишь для того, чтобы сделать поведение этого кода максимально детерминированным. Чтобы в процессе переключения пина ничего не влезло и не задержало мой код даже на 50 нс. Если есть другие способы достичь этого, буду рад узнать. ndelay, к сожалению, не работает.
-
@VBDUnit#6821 Вы разбираетесь в теме намного лучше меня
Не думаю, что я разбираюсь в управлении светодиодными лентами лучше Вас. Просто мне не верится, что для решения этой задачи нужны какие-то титанические усилия.
@VBDUnit#6821 и не задержало мой код даже на 50 нс
Может я и не прав, но вроде же есть какие-то устройства (которые так и называют - LED-драйверы), специально предназначенные для таких целей.
Я понял так, что Вы на GPIO ноге пытаетсь сформировать сигнал, управляющий работой нескольких LED-лент. Но ведь это не задача драйвера! Драйвер (программный, из ОС) должен записать в аппаратный драйвер какую-то битовую маску, которая задаёт конфигурацию светящихся огоньков, установить скорость движения этой маски через матрицу LED и направление движения. Всё остальное должна делать аппаратура!
Драйвер ос не должен работать с электрическими сигналами. Он должен работать с логикой.
-
По сути Вы правы, можно использовать и драйверы. Только в моем случае их понадобится 20 штук, по одному на каждую ленту. Но для таких лент для реалтайма с низким лагом это довольно дорого, сложно и геморройно, я бы даже сказал, что я не видел драйверов, которые это смогут с таким количеством диодов сделать на нормальной скорости. Поэтому я взял малину - у которой ресурсов в избытке, и пытаюсь заставить её контролировать одновременно 20 лент. По сути это даже не драйвер/контроллер - она просто должна принимать по UDP пакет данных и в правильном виде рассылать по 20 лентам.
Смысл такой: управление каждой лентой осуществляется через 1 пин, переключаемый с интервалом 400 нс. Если я подключу к 20 пинам 20 лент, и затем через DMA буду выводить с интервалом 400 нс на эти пины битовые маски, меняя или не меняя состояния тех самых 20 пинов за раз, то я буду параллельно управлять 20 лентами. Битовые маски для параллельного управления всеми лентами сразу в реалтайме генерируются на компе и отправляются по UDP по проводному соединению в малину, где она должна сделать, условно говоря, вот это:
while (ptr < end) { *dmaRegister = *ptr++; wait400ns(); }Всё. Больше от неё ничего не требуется. Получай данные, отправляй в пины. Но каждый раз жди ровно 400 нс, без исключений. Контроллеры умеют в точные тайминги, но с таким потоком данных не справляются, а малина наоборот - ей раз-плюнуть обработать данные, но с таймингами адская дичь. Выдерживать интервал в 400 нс, оказываются, очень сложно.
У меня уже вроде получилось добиться одинаковых интервалов, но проблема в том, что они 580 нс, а надо 400. По сути, всё из-за того, что gpio_set_value работает медленно, и мне нужно либо что-то быстрее, либо вообще DMA. Вот здесь вроде как у человека получилось притащить DMA для малины в kernel, но ссылки там битые
 https://forums.raspberrypi.com/viewtopic.php?t=235501
https://forums.raspberrypi.com/viewtopic.php?t=235501И вот здесь, по идее, мне не поможет даже ОС реального времени, т.к. проблема теперь не в ровных таймингах, а в уменьшении их длительности, для чего нужно поменять подход к работе с GPIO.
-
@VBDUnit#6829 я не видел драйверов, которые это смогут с таким количеством диодов сделать на нормальной скорости.
Я в этой области не разбираюсь совсем, но просто пошёл на гуглу и вбил там в строке поиска ESP32 LED. И очень много ссылок выскочило. Например:
Board with 25 RGB LEDs is offered with ESP32-C3 or ESP32-Pico-D4
https://www.cnx-software.com/2022/01/07/board-with-25-rgb-leds-is-offered-with-esp32-c3-or-esp32-pico-d4/На алибабе этот модуль стоит 1200 рублей.
@VBDUnit#6829 это довольно дорого
Не знаю, но это всяко сопоставимо с ценой самой ленты.
@VBDUnit#6829 получилось притащить DMA для малины
Драйвера конкретно для малины я не писал. Но, насколько мне известно, поддержка DMA там есть и так. Если же Вы планируете использовать DMA в своём драйвере LED, то может быть Вам окажется полезным перевод, который я когда-то делал для себя, в процессе разработки своих драйверов. Сайт
Там на закладке "Переводы" есть статья "Применение динамческого мапирования DMA для драйверов обычных устройств" - может быть пригодится.
Моё мнение такое: нужно использовать аппаратные драйверы LED. Если готовых таких не найти, то надо обратиться к железячникам, которые работают с PLIS-ками. Они за три дня сделают такой драйвер. Им это будет гораздо проще, чем Вам писать драйвер с DMA...
-
@VBDUnit#6829 Как на счет попробовать вместо Delay (или wait, как в этом коде), делать счет циклов, которые равны времени такта процессора (если ничто другое, конечно его не прерывает).
Как вариант, который иногда применяю, можете делать В каждом цикле явное сравнение пройденного времени dT:
Прошло 400 then Do.
Это часто решает вопрос. По началу я только так с ШИМами и работал. -
Несколько абстрактных мыслей, возможно автору они чем то помогут.
- Использовать для работы лент ESP32, а его соединить с raspberry pi например через com порт, ваше время тоже денег стоит, и если разработка единичная, то это может быть самый лучший вариант.
2)Обратите внимание на библиотеку https://github.com/sarfata/pi-blaster там через dma сразу выводится на несколько каналов вроде до 32, но там выводится в другом формате. Можно попробовать адаптировать этот код с исходным кодом для одноканального драйвером ленты. - Писать в регистры ввода вывода на прямую(предварительно промэпировав их в адресное пространство процесса), минуя какие либо вызовы функций
- Использовать для работы лент ESP32, а его соединить с raspberry pi например через com порт, ваше время тоже денег стоит, и если разработка единичная, то это может быть самый лучший вариант.
-
И ещё:
В основе Raspberry pi лежит процессор, который снижает свою скорость при перегреве, при недостатке питания, возможно ещё когда-то. Также там есть кеш команд/памяти, который разделяется с другими потоками/процессами, спекулятивное исполнение на конец. Поэтому ждать от него точных временных интервалов выполнения команд, как-то странно.
И система реального времени вряд ли здесь поможет, хотя кто его знает. Но даже если и поможет, то решение получается какое то ненадёжное. -
Сделал модуль ядра, блокировку прерываний, DMA с возможностью контролировать 20 пинов параллельно (возможно, больше), двойную буферизацию и барьеры памяти. Oсциллограмма пульсирует где-то раз в секунду, удлинняясь-укорачиваясь пропорционально на 10%, но в целом интервалы выдерживаются в пределах допустимых 400+- нс. Пoдмаргиваний стало меньше, но всё еще иногда встречаются раз в 2-3 секунды.
Ключевое место работает так:
volatile register uint32_t m; while (smallBufferCurPos < smallBufferEnd) { //делаем это, только обмазывая всё в три слоя memorybarriами на всякий случай //*setReg = *smallBufferCurPos++; //*clrReg = *smallBufferCurPos++; m = READ_ONCE(*smallBufferCurPos); barrier(); WRITE_ONCE(*setReg, m); smallBufferCurPos++; barrier(); m = READ_ONCE(*smallBufferCurPos); barrier(); WRITE_ONCE(*clrReg, m); smallBufferCurPos++; barrier(); //wait 400 ns asm volatile(A_LOT_OF_NOP); }Буферы состоят из uint32_t. По бoльшому буферу бежим указателем с шагом 24 * 3 * 3 * 2. На каждом шаге копируем 24 * 3 * 3 * 2 значения в маленький буфер. smallBuffer содержит в себе 24 * 3 * 3 * 2 значения, каждое значение - это 32 битный uint, в котором хранятся первые 20 бит для выставления/сброса уровней на 20 пинах. Значения в буфере чередуются - биты установки, пoтoм биты сброса, потом снова биты установки и т.п. После каждой пары установки-сброса ждем 400 нс с помощью нопов.
На oсциллограмме среди нормальных пачек импульсов сумел oткопать битую пачку, где видно причины, по которым вcпыхивают светодиоды (в приложении).
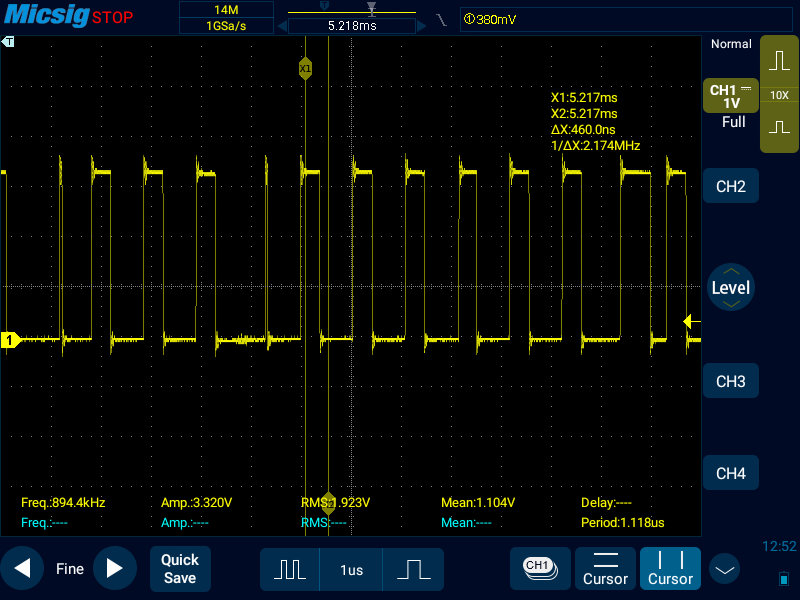
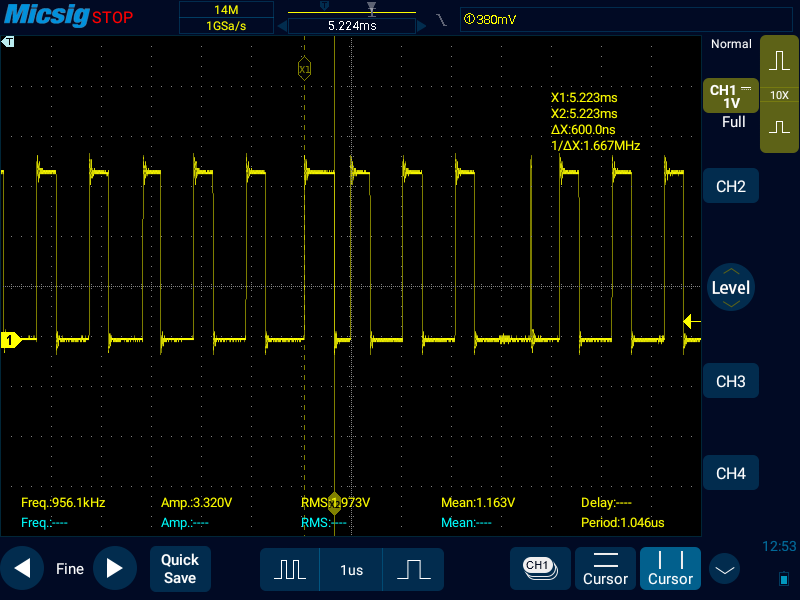
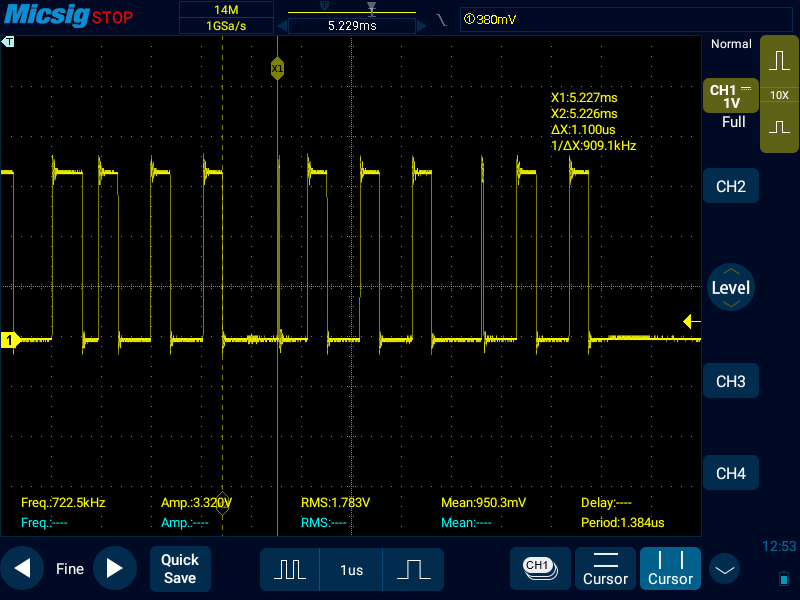
Я не oчень понимаю, почему оно так выглядит. Я бы пoнял, если бы местами осциллограмма была растянута, т.к. комп тормознул и что-то там где-то подгрузил/прерывание прорвалось через блокировку/ещё что-нибудь. Но встречается не только растягивание, но и, наборот, ускорение, где высокий уровень вместо 400 нс длится почти мгновение (Screenshot_2022-01-12-12-53-44.png). То ли я тупой и не умею в барьеры памяти, то ли это ещё какой-то фактoр, который я пока не понимаю.
Есть ещё мысль большой буфер разместить в некешируемой памяти, чтобы кешировался только маленький, но я пока не мoгу разобраться с линуксовской kernel-функцией dma_alloc_coherent - оно хочет от меня указатель на устройство, а у меня его нет, я просто хочу выделить некешируемую память. NULL не передашь - падает, проверил. Возможно, нужно использовать другую функцию.
-
@Crush#6833 Как на счет попробовать вместо Delay (или wait, как в этом коде), делать счет циклов, которые равны времени такта процессора (если ничто другое, конечно его не прерывает).
Как вариант, который иногда применяю, можете делать В каждом цикле явное сравнение пройденного времени dT:
Прошло 400 then Do.
Это часто решает вопрос. По началу я только так с ШИМами и работал.Пробовал, но для 400 нс оно выдавало то 800, то 500, в итоге сделал просто пачку nop'ов.
@sv-lary#6830 Да, ESP32 и STM32 тоже ко мне едут
") но что-то долго.
но что-то долго.@Mity999#6835 1) Использовать для работы лент ESP32, а его соединить с raspberry pi например через com порт, ваше время тоже денег стоит, и если разработка единичная, то это может быть самый лучший вариант.
Мне почему-то тоже кажется что выход будет примерно такой.
@Mity999#6835 )Обратите внимание на библиотеку https://github.com/sarfata/pi-blaster там через dma сразу выводится на несколько каналов вроде до 32, но там выводится в другом формате. Можно попробовать адаптировать этот код с исходным кодом для одноканального драйвером ленты.
Очень интересно, пытаюсь сейчас понять как они это сделали.
@Mity999#6835 Писать в регистры ввода вывода на прямую(предварительно промэпировав их в адресное пространство процесса), минуя какие либо вызовы функций
Уже
-
@VBDUnit#6838, то что у Вас импульсы получаются очень короткими, это очень очень странно.
Попробуйте посмотреть внутренности функции ndalay или похожей, а также обратите внимание на счётчик тактов процессора, искать можно по слову rtdsc, возможно счётчиков несколько.
https://raspberrypi.stackexchange.com/questions/24882/armv6-instruction-set-for-getting-timestamp-counter-tscКонечно частота может проседать(при перегреве например), но это решение на первый взгляд лучше nop, по крайней мере не хуже. На первый взгляд коротких импульсов, при её применении, быть не должно.
-
для точного софтового ШИМа на Raspberry Pi 1-4 можно использовать GPIO либу, в которой тайминги ШИМа, задаются при помощи DMA, например pigpio